FastAPI is built on top of Starlette, which is an ASGI framework. That makes it ideal for building async web services in Python.
Async code can be more efficient only when it comes to IO operations like reading from a database – that's like 99% of web use cases. But you might be surprised to know that even for non-IO operations, async functions will perform better in FastAPI.
Consider this application:
from fastapi import FastAPI
app = FastAPI()
@app.get("/nonasync")
def nonasync_endpoint():
return "Hello Non-Async"
@app.get("/async")
async def async_endpoint():
return "Hello Async"
The /nonasync endpoint is bound to a regular Python function, and the /async endpoint is bound to a coroutine.
I'm running the Uvicorn server in production mode:
uvicorn main:app --port 3000
And load test using Apache HTTP server benchmarking tool:
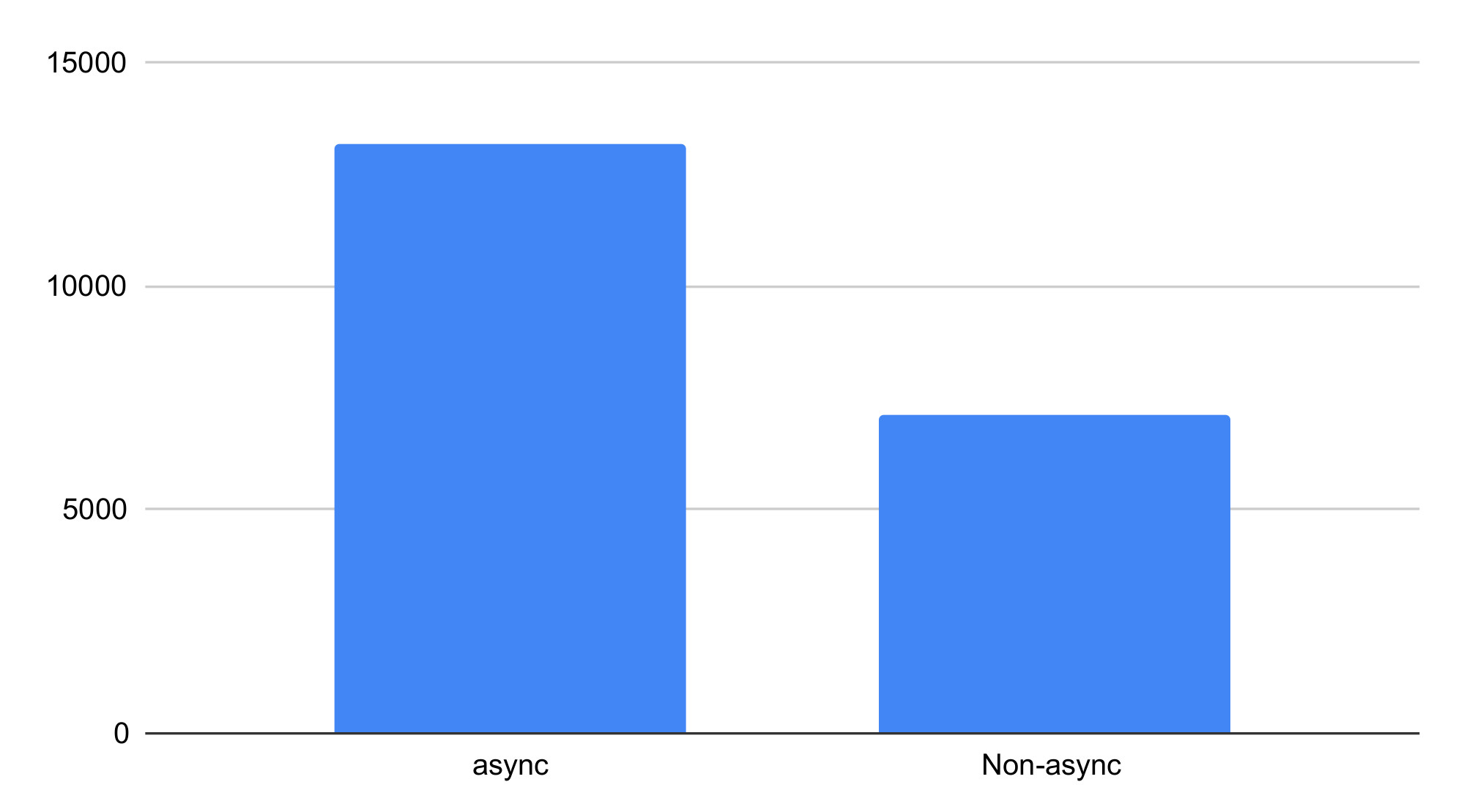
$ ab -n 1000 -c 100 http://localhost:3000/async
Requests per second: 13190.52
$ ab -n 1000 -c 100 http://localhost:3000/nonasync
Requests per second: 7103.43
I ran these tests on an Intel i9-13900K CPU.
The async endpoint is 85% faster than non-async, even though there's no IO.
Why?
We keep hearing there's no benefit in using async code when there's no IO. Why isn't it true here?
This is a call chain starting from a FastAPI route handler when the endpoint is not a coroutine:
- FastAPI: get_route_handler
- FastAPI: get_request_handler
- FastAPI: run_endpoint_function
- Starlette: run_in_threadpool
- AnyIO: anyio.to_thread.run_sync
- Starlette: run_in_threadpool
- FastAPI: run_endpoint_function
- FastAPI: get_request_handler
The answer is anyio.to_thread.run_sync. It allows running a blocking function in a worker thread. It lets the event loop continue running other tasks while the worker thread runs the blocking call. When a function is not a coroutine, FastAPI uses Starlette's run_in_threadpool to execute the endpoint function, which ultimately uses anyio.to_thread.run_sync.
Running a function in a worker thread and waiting until it's done adds overhead for each API call.
Use More CPU
I added some dummy operations to make sure the endpoints represent a real CPU-intensive task:
def cpu_intensive_task():
c = 0
for i in range(0, 1000000):
c += 1
@app.get("/nonasync")
def nonasync_endpoint():
cpu_intensive_task()
return "Hello Non-Async"
@app.get("/async")
async def async_endpoint():
cpu_intensive_task()
return "Hello Async"
And the result is even more surprising:
$ ab -n 1000 -c 100 http://localhost:3000/async
Requests per second: 31.47
$ ab -n 1000 -c 100 http://localhost:3000/nonasync
Requests per second: 15.56
The async endpoint is more than 2 times faster in this case.
Multi-worker
Out of curiosity, I ran Uvicorn with 32 workers since my CPU has 32 threads.
uvicorn main:app --port 3000 --workers 32
And the results are:
$ ab -n 1000 -c 100 http://localhost:3000/async
Requests per second: 454.22
$ ab -n 1000 -c 100 http://localhost:3000/nonasync
Requests per second: 367.90
The async endpoint is 23% faster this time. The reason is that there are more worker processes available, and given the number of concurrent requests is the same, fewer threads are needed per process. With fewer threads, there's less context switching and overhead for each process, which ultimately reduces the cumulative overhead of run_in_threadpool.
Conclusion
Always use async functions to define your FastAPI endpoints unless you're dealing with blocking IO, no matter if they're CPU-bound or IO.